本博客用于简历排版, 每一份简历都是根据职位描述的内容进行针对性的撰写, 其中个人信息, 工作履历和教育背景部分因为隐私问题以及其高可重构性略去, 后期导出后按需添加.
个人信息
姓名: 李伟岸 DoB: 1991-08-01 性别: 男
学历: 理学硕士研究生 电话: 2B Specified 邮件:2B Specified
教育经历
2015.08 - 2016.11 硕士 曼彻斯特大学(英) 高级计算机科学和信息技术管理
2011.09 - 2015.07 本科 沈阳工业大学 信息与计算机科学
求职意向
工作性质: 全职 目标职能: Java后端开发工程师 目标地点: 广州
工作技能
对Spring,Mybatis,SpringMVC构建系统有深刻认识。能根据MyBatis源码进行个性化定制可组装的动态SQL。
Till Chapter 20精通Spring Boot整合web开发异常处理, 静态资源处理,跨域问题解决,定时任务,接口文档整合等常见业务场景, 阅读过相关源码。
Till 30熟练应用 Spring Cloud(Eureka、Ribbon、OpenFeign、Hystrix, Config, Gateway)以及alibaba的(Nacos、Sentinel) 等分布式组件, 并能对不同微服务业务场景分析组件优劣势给出选型方案相关的合理建议。
Till 40精通分布式系统的常见权限框架,对Shiro和Spring Security作为权限框架实现SSO继承CAS,LDAP等操作熟练。阅读过源码。
Till 60精通Nginx作为反向代理服务器,负载均衡,动静分离,URL rewrite及其安全访问控制使用相关的操作。
Till 65精通MySQL Innodb 存储引擎 Buffer Pool、事务、锁、索引底层工作原理,能根据 explain执行计划优化 SQL。
Till 80深入理解Redis数据结构、持久化、复制、主从、集群工作原理,熟悉缓存雪崩、缓存穿透、缓存击穿解决方案。
Till 90对Kafka RocketMQ作为消息中间件的常见实用场景有生产使用经验。
Till 100深入理解JVM底层工作原理和垃圾回收机制,熟练使用jstat、jmap、mat进行jvm调优并制定jvm模版。
Till 120了解并使用过Hadoop、Hive、Flume,zookeeper等大数据相关技术.
Till 130了解并使用过持续集成组件Jekins,容器化部署以及自动化编排 docker k8s.
Till 140系统工具: Linux, git, SSH 客户端, postman, Jmeter,arthas.
Till 150
搭建过个人Hexo博客, 对上述大部分知识点进行过详细记录 并持续学习更新中。
工作经历
2019.06 - 至今 2B Specified 集团职能-数字化办公室-数据治理与产品技术
2017.03-2019.03 2B Specified 后端一组-Java 开发
项目经验
1. 数据资源开放共享项目
背景: 该项目是数字化办公室的数据银行产品下属的模块,与其他四个模块(数据治理,数据安全, 元数据, 数据资产)共同协调对接, 是大部门用以对外(指集团其他职能部门, 而非集团外)提供数据服务的。
工作流程:
业务用户在元数据申请需要的服务(对应一张业务数据表), 申请流程走完该表就流转到数据治理模块,显示为已上架的状态, 允许继续注册。
用户登陆数据治理模块, 查询到刚才申请的表, 点击页面注册按钮, 跳转到开放模块的前台页面。 跳转的过程中会带过来一个tableKey(该tableKey是治理模块按照不同系统, 不同库,不同表自定义的主键key, 用来区分不同表, 具体规则:系统id-库名_表名称)。
除了tableKey还会附带该tableKey对应的元信息: schema,table,fields,业务owner,ITowner,mip, 更新频率, 所属事业部等。用户在开放模块点击注册会触发服务生成。
根据这些信息开放后台进行如下处理:
a). 查询该tableKey对应的表在开放后台是否有预先配置成数据源。没有则提示用户配置并终止。
b). 如果已经配置查询, 则查询该tableKey对应的数据表类型是否是针对有特殊时效性的敏感指标, 如果是即表明数据源在字典表中配置, 如果不是则在数据源表配置。
c). 接下来生成数据集, 接口,和服务。 服务对外公开,以供访问具体业务数据。
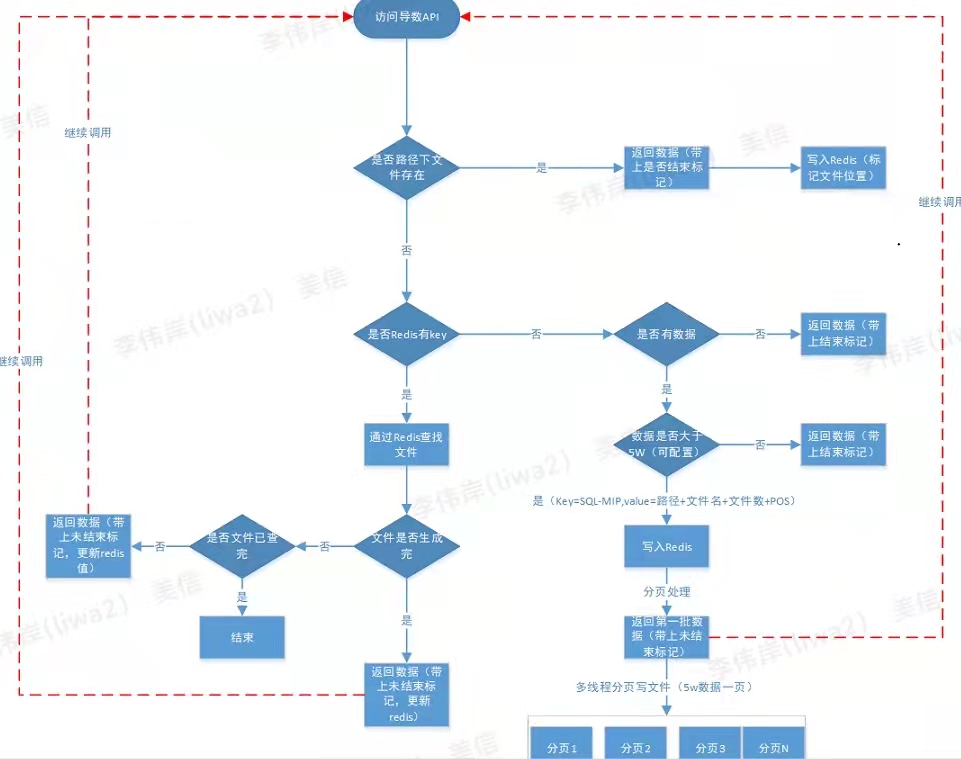
目前该项目迭代版本已经支持: 从页面直接填写元信息注册, 数据治理跳转注册, 多个批量注册(excel导入), 查询数据服务热点数据缓存。
2. IICC接口平台
该项目专门用来给工业互联网(集团各个工厂大屏)提供数据支持。 用来跟进员工出勤/转岗/离职率, 生产用料准备进度,生产进度,按时完工率, 物流进度, 按时交付率等主要生产指标的数据逻辑处理和可视化呈现。 主要思路和上一个类似, 只是该项目用到的数据源相对比较少, 统一配置且在启动项目时统一加载(每次如果有新数据源就需要重启项目,而上一个项目是直接在配置后即刻加载生效)。而且该项目是在简化MyBatis原生代码的基础上提供动态SQL的支持。 使得ETL同事也可在该平台进行接口开发。
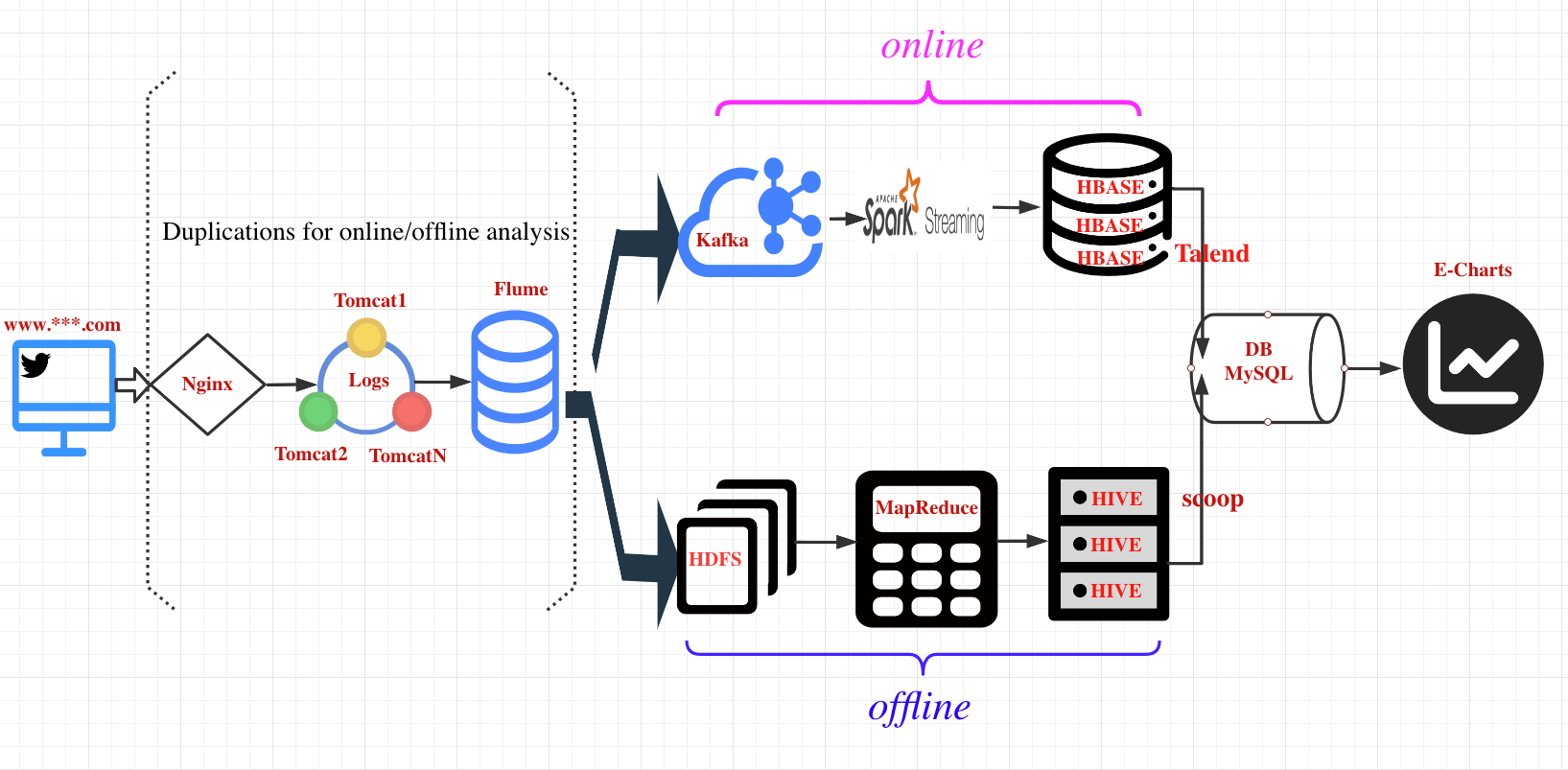
3. 日志收集
根据使用的Flume版本,查询官方文档,在服务器上配置log4JAppender文档发送数据到Flume主机对应端口。
使用Flume的avro类型的Source, 获取服务器行的日志数据,配合rege_ extractor类型的interceptor将时间戳加到事件头中。使用HDFS类型的Sink将日志扇出到HDFS的指定目录下,并在路径上拼接了格式为reportDate=%Y-%m-%d的时间戳,设置其只按照时间(而非文件大小或数量)进行滚动生成最终的文件。数据类型设置为DataStream,为了更好的本地化,将时区设置为GMT+8 最后将Source和Sink绑定到 Memory类型的Channel上形成最终的Flume agent配置文档。
利用Hive工具
a) 创建数据库LogAnlDB并进入:
b) 创建外部分区表原表Original按照日期partition(含有所有前端埋点收集到的数据指标近20项)
c) 数据清洗表dataClear,只提取原表中与分析业务相关的8个指标.
d) 将原表中对应8项指标数据插入到数据清洗表中
e) 对清洗表中数据进行HQL操作得到中间值,转存到临时表Temp中。(Temp只含有3列:分别是分区值即日期, 指标名称和指标对应值)
f) 创建最终的统计表Stat,并将Temp中临时存储指标对应的值(共8行)查询出来插入Stat统计表中作为一行统计记录。
使用Sqoop工具命令将hive中的数据落地到MySQL中。
将3,4中涉及的代码编写HQL脚本文档,结合linux的定时任务crontab将其设置为每天凌晨进行自动采集数据分析。